我们为什么要换TiDB
在业务增长的情况下,伴随的是数据量的剧增,在传统Mysql的服务体系下,千万甚至上亿的数据对于数据存储和查询来说,似乎只有通过增加Mysql实例 ,分库分表等措施来应对,通常这些操作对于研发和运维来说都是很痛苦的,并且在做数据同步时更是需要小心翼翼
但此时另一端的TiDB应运而生,他的优点在于:
1.天生就是分布式的数据库,可以无限扩展,不用在考虑分库分表
2.对于大数据友好,支持Spark对主库进行实时查询
3.可以做到故障自动恢复
4.从Mysql切换至TiDB的成本对于研发来说非常小,TiDB支持Mysql的语法(比较严格,某些Mysql的特别语法TiDB并不会通过),并且使用kv结构模拟了关系型结构
TiDB的架构是怎样的
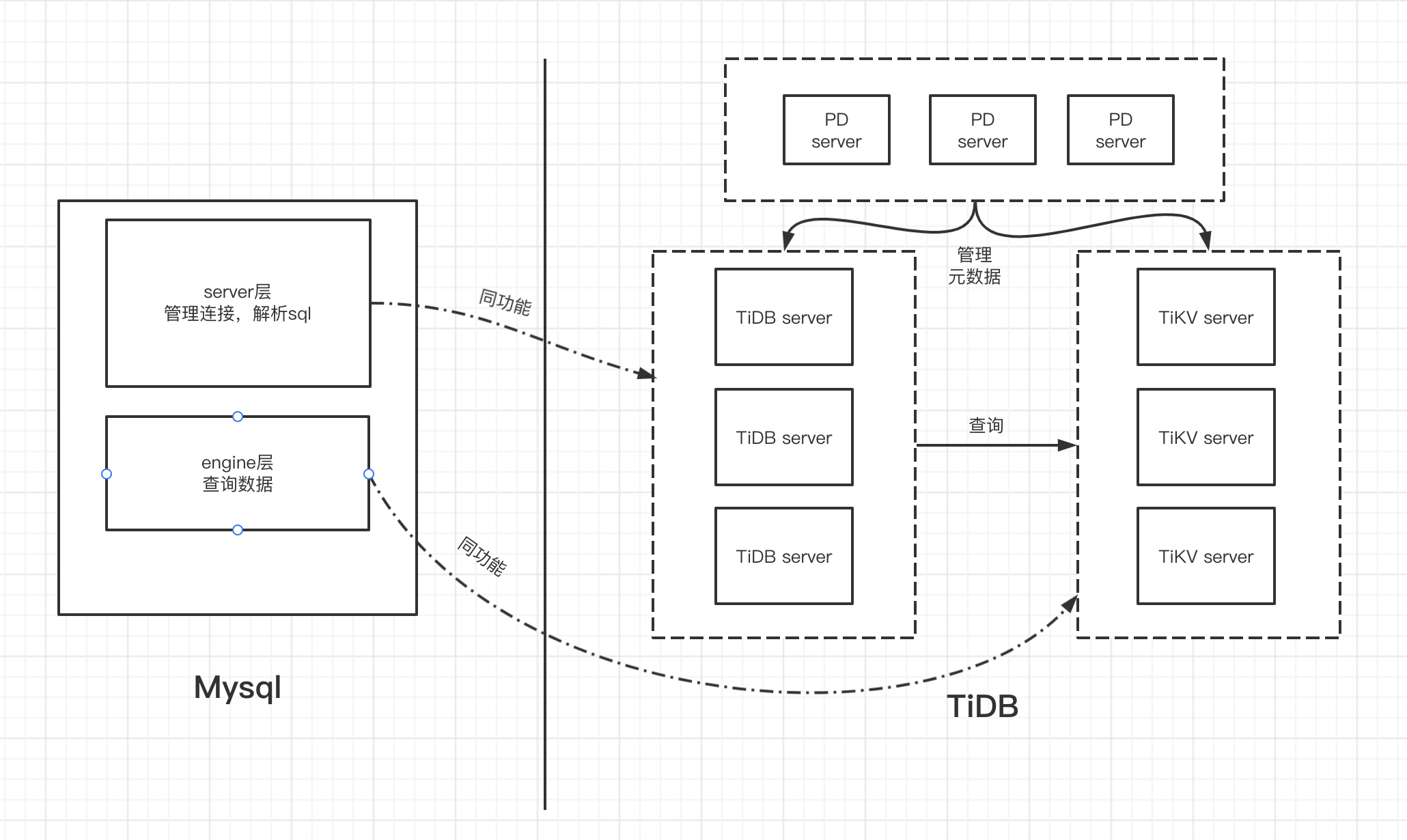
对于Mysql来说,架构基本可以分为server层和engine层,server层负责连接、sql解析等,engine层负责数据存储,当Mysql要进行扩展时,传统的扩展方案,是对其进行多节点部署,也就是说多一个节点,就会多一套server和engine,看起来很重对不对
而对于TiDB来说,他把整体架构拆的更细,TiDB server等于Mysql的server层,TiKV server等于Mysql的engine层,而PD server则是TiDB的元数据管理层,是相对语Mysql来说新加的一个层,我理解其实跟Redis的sentinel差不多,在TiDB需要扩展时,可以根据具体的业务情况进行扩展,当计算能力/处理sql的能力到达瓶颈时,可以增加TiDB server节点数量扩展计算能力,当存储出现瓶颈时可以通过增加TiKV server来扩展存储能力,这样以来就变得轻盈又灵活
TiDB是怎么存储数据的
TiDB的存储在于TiKV,这个服务集群来存储数据,TiKV整体就是一个大型的kv存储结构,TiKV的底层是通过rocksdb来进行数据存储,这个存储引擎可以高效的利用SSD
TiKV里面有一个重要的概念,region,可以理解为是一段连续的key组成的数据段,这是TiDB里面数据传输和同步的最小数据单元,所有的数据会被划分成n个region,然后由PD server来尽可能平均的分配到不同TiKV节点上
当然每个TiKV节点上的数据也会有备份在其他节点上,这样不会在节点挂掉的时候导致数据丢失,TiKV之间在相互数据备份的时候也是通过region为单位备份的,每个region都会有备份在不同的节点中,原理是不同节点之间相同的region,会构成一个raft group,其中会有一个leader来对其他follower传输数据,当leader挂掉后,各个节点之间会通过raft选举出一个leader,保证数据安全