业务系统在docker内内存持续增大,导致频繁被系统kill
使用 cat /var/log/message 查看kernal日志得到是因为oom被系统kill
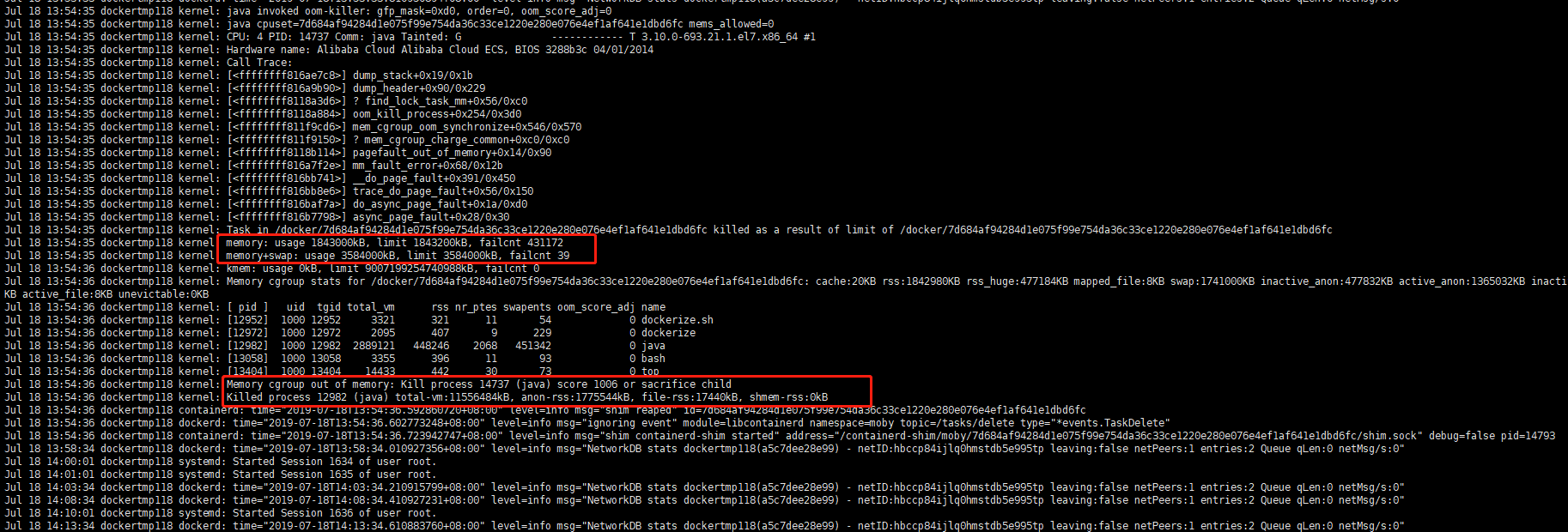
使用docker stats 查看容器运行状况

docker run 命令如下(使用了lxcfs,事实证明最后的解决方案并不需要用到lxcfs)1
docker run -m 2800M --memory-swap 3500M --memory-swappiness 60 -p 9011:9011 -dit --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --restart=always -e CATALINA_OPTS='-Xmx200m' --name=${project} --network=host -v /etc/localtime:/etc/localtime:ro --hostname=alioracle -v logs${project}:/tools/tomcat8/logs -v /tools/application2.properties:/tools/tomcat8/bin/application.properties $extrarunops scm.nicezhuanye.com:6555/$p:$version`
设置-Xmx200m
(使用-swapiness可以决定程序使用交换内存的意愿,0-100,0表示绝对不会使用交换内存,越大使用的概率越大,设置交换内存后,程序把交换内存跑满,一样会被kill)
初步怀疑java heap泄露
使用 docker exec -it schedulercore2 bash -c "wget https://alibaba.github.io/arthas/arthas-boot.jar && java -jar arthas-boot.jar" 进入容器内
使用 arthas的dashborad命令查看java heap并没有超过限制
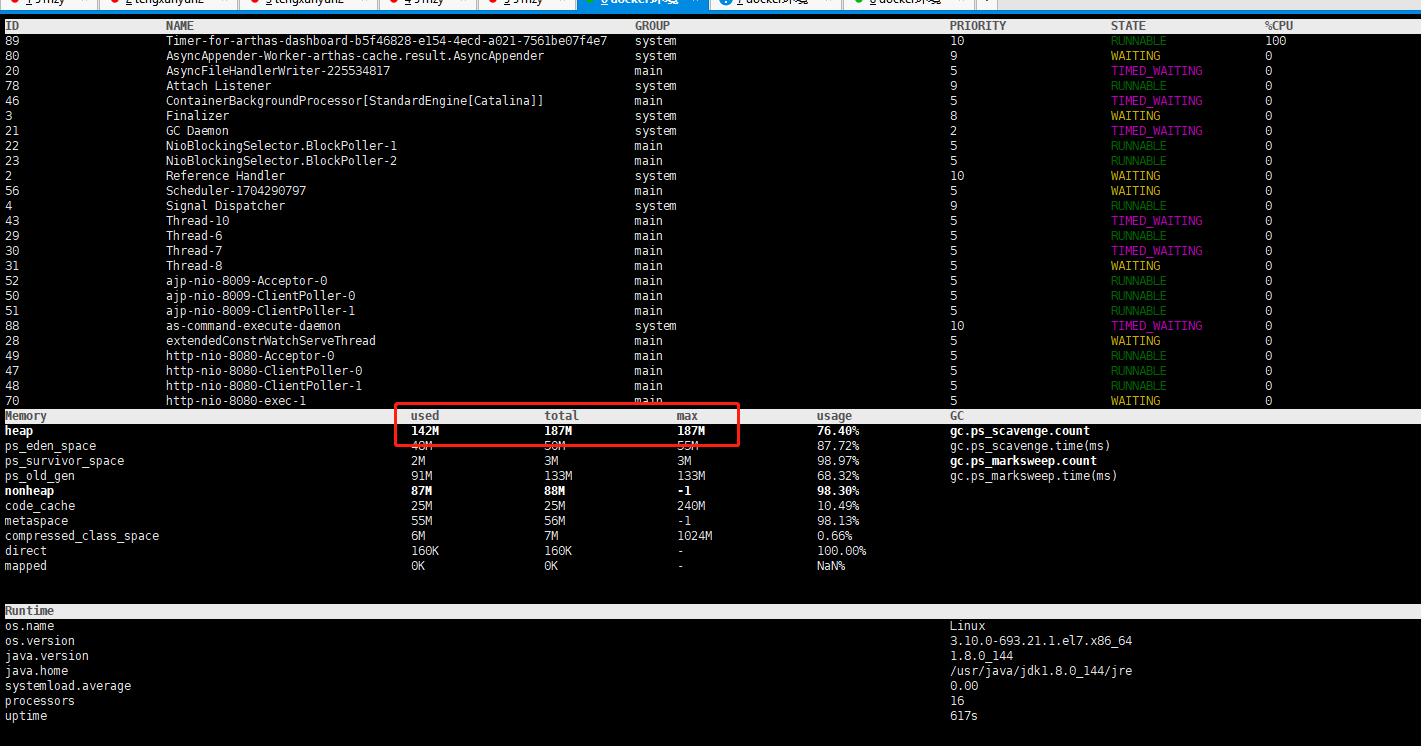
所以有可能是堆外内存超了
使用pmap <pid> -X来查看java进程的内存情况
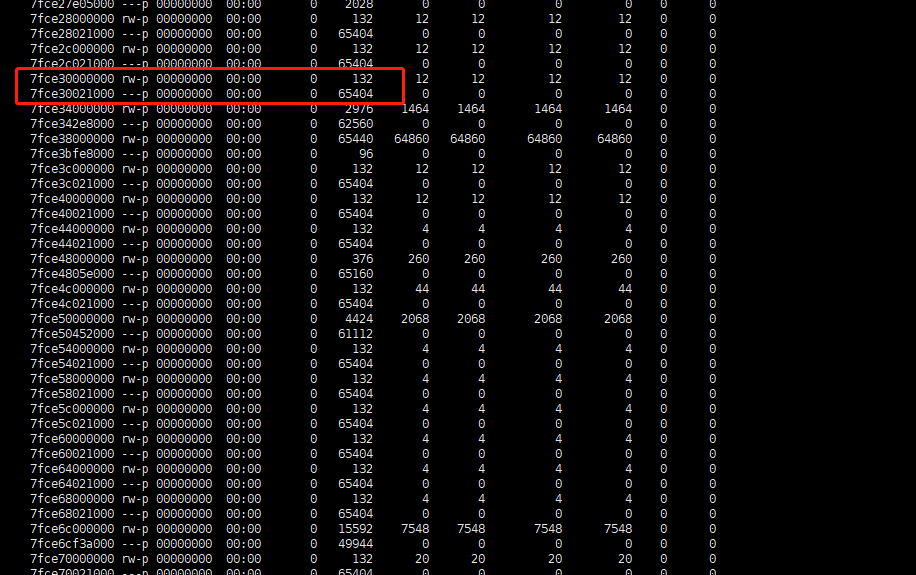
发现很多两个一组,加起来等于65536kb也就是64mb,仔细观察大多都是132kb的堆是rw权限,650000多的是无权限的内存块
使用gbd attach <pid> 到java进程上
使用命令 dump memory <path> <start address> <end address>将内存块dump到磁盘上,(例如 dump memory /tools/core.dump 0x7fce18000000 0x7fce18000000+65536,开始地址为pmap中的内存地址直接加0x前缀,结束地址为开始地址加内存块地址长度)
使用strings命令查看dump的内容,发现无可查看内容(有可能是无用内存)
查看网上资料,网上也有很多大老遇到了类似的问题
http://ju.outofmemory.cn/entry/105474
https://blog.csdn.net/ityouknow/article/details/84038718
初步得到可能是glibc内存分配的原因
可以添加系统变量MALLOC_ARENA_MAX=4 来限制堆的使用
尝试后发现64mb的堆的确少了,但是还是会出现内存爆炸的现象
之后尝试文章中将glibc替换为谷歌研发的tcmalloc后,成功稳定住了堆外内存
使用yum install gperftools-libs.x86_64
在/usr/lib64中可以找到libtcmalloc.so.4
将该文件添加到docker镜像中
DOCKERFILE中添加 LD_PRELOAD="/usr/lib64/libtcmalloc.so.4.1.0" 环境变量
这样就将glibc替换为了tcmalloc