前言
实际项目中使用线程池的场景往往很多,比如批量刷数据,批量获取数据等用来提升接口或代码运行速度,亦或是通过提交异步任务来让某些不是特别需要实效性的任务异步执行,减少当前主线程的运行时间,而jdk也给我们提供了Executors类来支持我们很方便的创建和使用线程池,spring也封装了线程池加强使用体验。
但是在项目中,我们更多的是能看到各式各样的线程池使用情况,有自己创造的,也有直接使用公共的(例如CompletableFuture),这些在使用上完全没有问题,但是有如下几个弊端:
- 1.线程池容易在配置上踩坑,比如线程池的队列打满后,才会触发线程池新创建线程,如果使用的是无界队列,那么其实最大线程数的参数(
maximumSize)就失效了- 2.部分版本的线程池有bug,比如java8中的
Executors.newSingleThreadExecutor()就会出现提前GC被关闭的问题(详见这里),而代码中大家经常又会复制粘贴某些代码,就导致有问题的代码会污染项目- 3.在项目变得庞大起来后,过多的线程池,导致线程数量剧增,频繁切换线程导致对系统资源的消耗,其实过多的线程并不能够带来更多的性能上的提升,cpu一共就固定的几个核心,也就是说他最多并行执行的线程也就是固定的数量,而且除开项目中我们可以把控的线程数之外,第三方依赖和系统进程都会有线程使用cpu,所以对于线程数的设计,需要针对项目去分析
- 4.往往不知道如何配置线程池的参数,也往往不知道线程池的利用率是怎么样的,上线后不知道效果如何
- 5.线程池往往没法直接继承父线程的上下文,对于需要使用
traceId等跟踪的情况下,会比较麻烦
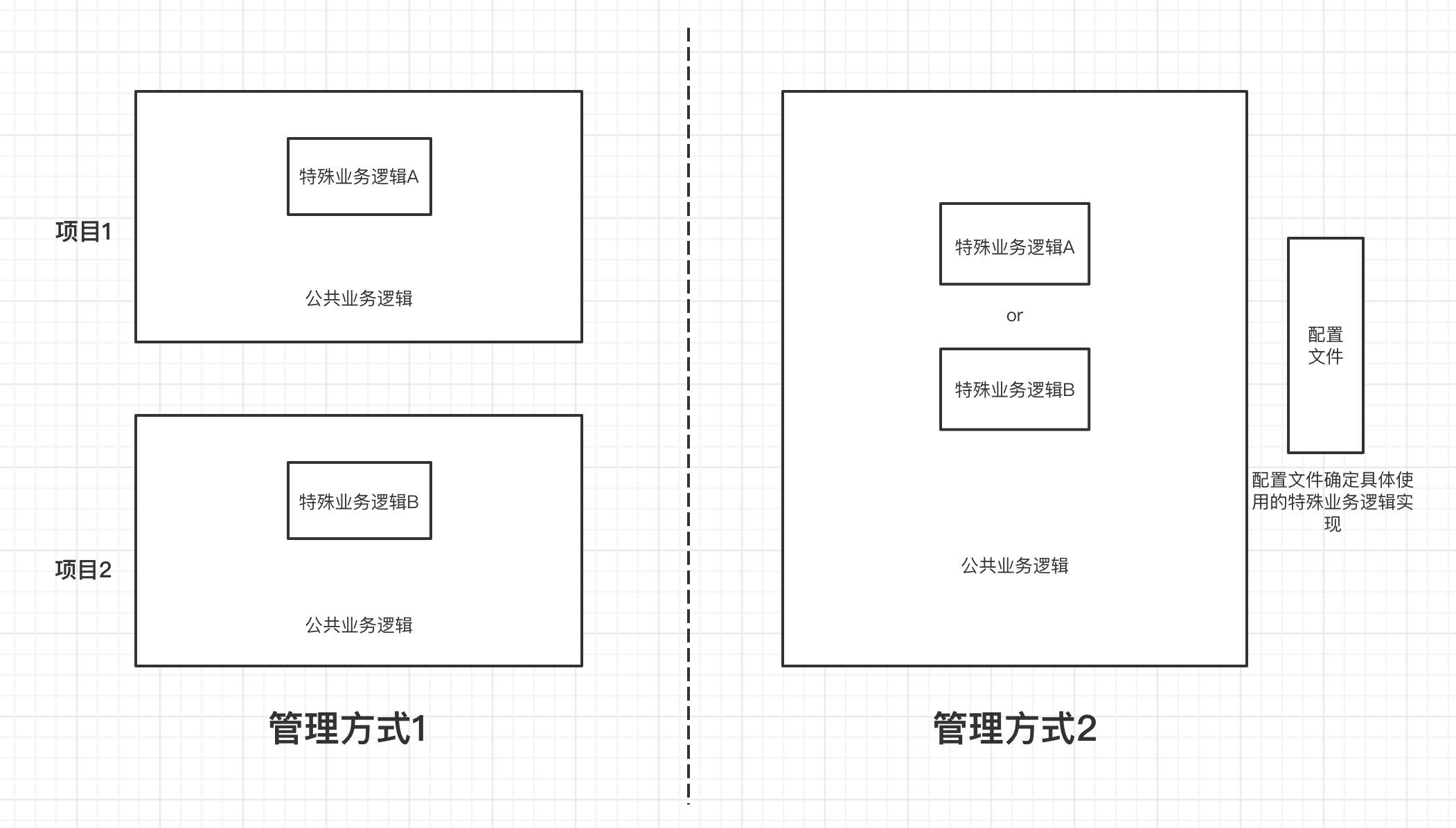
我们需要提出一个解决方案,来解决上述的问题,在我们公司实际项目探索中,发现我们使用线程池的方式多种多样,如下图